jVector 簡介
1. 簡介
在人工智慧和資訊檢索領域,經常需要在資料集中搜尋相似的向量。許多系統,例如推薦系統、文字情緒分析或文字生成,都利用了向量搜尋。
在本文中,我們將探索 jVector 庫,以便從資料集和向量搜尋中有效地建立索引。
2. 理解向量搜尋
在資訊檢索的脈絡中,我們可以將單字表示為向量,其中每個位置代表一個因子。這些因子代表所選參數與向量化單字的似然值。例如,單字apple可以使用 ('fruit', 'blue') 參數集向量化為[0.98, 0.2] ,因為蘋果很可能是水果,而不太可能是藍色的。
在這樣的系統中,我們可以使用距離函數來找出與apple相似的字。例如, banana這個字可以表示為[0.94, 0.1] 。根據距離函數, apple和banana這兩個詞是相似的,因為它們的參數很接近。
所有這些都歸結為向量搜尋的本質,即創建一種機制來以高信心和高效率找到相似的向量。
3.jVector核心結構簡介
由於維數災難的影響,高維度問題和大數據集的向量搜尋問題對經典向量搜尋演算法來說是一個挑戰。因此,為了成為一個高效且可擴展的向量搜尋處理器,jVector 採用了兩種現代結構:分層可導航小詞 (HNSW) 圖和磁碟近似 K 最近鄰 (DiskANN) 演算法。
HNSW 是一種圖形結構,它透過使用層(或層次結構)以及這些層之間的連結跳過搜尋空間中不需要的向量來優化搜尋:
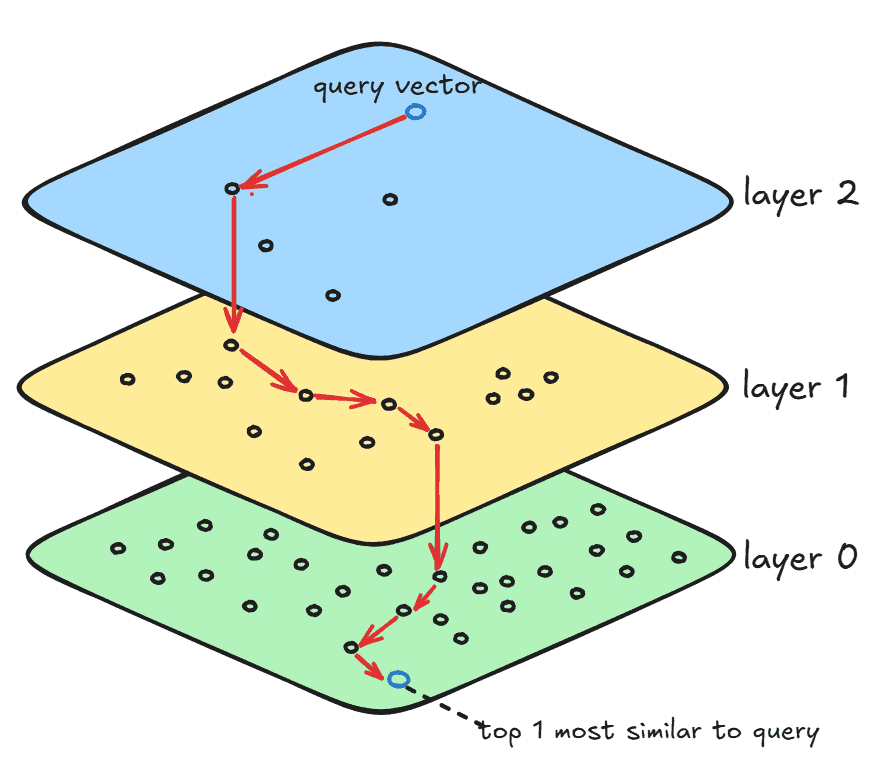
第layer 0包含搜尋空間中的所有向量,最終的搜尋結果也儲存於此。 layer 1包含layer 0,但其聚類向量數量比layer 0更多。最後, layer 2包含layer 1的子集,其聚類向量數量甚至比所有其他層都更少,但聚類向量數量更多。層數取決於搜尋空間中的向量數量和圖的度數。這些層是在索引結構建構過程中建構的,我們將在後續章節中看到。
對於每一層,jVector 都會執行一個 DiskANN 演算法實例,以便在該層內搜尋相似的向量。此外,HNSW 會建立長鏈接,將兩個不同層中的相同向量連接起來。因此,當 DiskANN 完成layer 2, 也就是說,當找到局部最小值時,就從下一層中的同一個向量(使用層間的長鏈結)重新開始搜索,直到到達layer 0 。最後,當 DiskANN 在最底層完成搜尋後,搜尋就完成了。
4.基本配置
建置 jVector 所需的唯一步驟是新增jVector Maven 依賴項:
<dependency>
<groupId>io.github.jbellis</groupId>
<artifactId>jvector</artifactId>
<version>4.0.0-rc.2</version>
</dependency>5. jVector 中的基於圖的索引
在本節中,我們將學習如何建立 HNSW 索引結構並將其保存在磁碟上。
5.1. 建立索引
讓我們定義一種方法,使用先前載入的向量和檔案路徑來持久化索引:
public static void persistIndex(List<VectorFloat<?>> baseVectors, Path indexPath) throws IOException {
int originalDimension = baseVectors.get(0)
.length();
RandomAccessVectorValues vectorValues = new ListRandomAccessVectorValues(baseVectors, originalDimension);
BuildScoreProvider scoreProvider =
BuildScoreProvider.randomAccessScoreProvider(vectorValues, VectorSimilarityFunction.EUCLIDEAN);
try (GraphIndexBuilder builder =
new GraphIndexBuilder(scoreProvider, vectorValues.dimension(), 16, 100, 1.2f, 1.2f, true)) {
OnHeapGraphIndex index = builder.build(vectorValues);
OnDiskGraphIndex.write(index, vectorValues, indexPath);
}
}我們首先取得資料集的維度數,並將維度儲存在RandomAccessVectorValues中,它本質上是向量值清單的有效包裝器。
然後,我們定義一個BuildScoreProvider作為計算距離的基礎。在本例中,我們使用VectorSimilarityFunction類別中的歐氏距離計算器。
然後,我們使用try-with-resources從GraphIndexBuilder類別中開啟一個AutoCloseable資源。它的一些參數會影響索引的建構方式,直接影響向量搜尋的品質和速度,因此讓我們按順序逐一介紹它們:
-
scoreProvider:分數提供函數 -
dimension:向量的維數 -
M:圖的最大度數;當然,如果我們將此值設定得較低,則會建立更多層 -
beamWidth:DiskANN 處理 top-K 近鄰時波束搜尋的大小 -
neighborOverflow:定義圖的最大度數在建構過程中可以暫時溢出該因子;必須大於 1 -
alpha:DiskANN 參數,用於控制解決方案的多樣性;必須為正 -
addHierarchy:設定 HNSW 結構是否應該有層
然後,我們呼叫build()函數,根據建構器和資料集建構 HNSW 結構。最後,我們將索引寫入persistIndex () 函數提供的參數檔路徑中。 方法。
5.2. 測試索引創建
讓我們使用一個簡單的 JUnit 測試來說明客戶端程式碼如何使用我們的persistIndex ()方法:
class VectorSearchTest {
private static Path indexPath;
private static Map<String, VectorFloat<?>> datasetMap;
@BeforeAll
static void setup() throws IOException {
datasetVectors = new VectorSearchTest().loadGlove6B50dDataSet(1000);
indexPath = Files.createTempFile("sample", ".inline");
persistIndex(new ArrayList<>(datasetVectors.values()), indexPath);
}
@Test
void givenLoadedDataset_whenPersistingIndex_thenPersistIndexInDisk() throws IOException {
try (ReaderSupplier readerSupplier = ReaderSupplierFactory.open(indexPath)) {
GraphIndex index = OnDiskGraphIndex.load(readerSupplier);
assertInstanceOf(OnDiskGraphIndex.class, index);
}
}
}我們首先使用loadGlove6B50dDataSet () 輔助方法將資料集載入到單字與其向量表示的映射中,名稱為datasetMap 。此外,我們建立一個Path來儲存索引的輸出,並將向量和路徑傳遞給persistIndex()方法。因此,在執行帶有@BeforeAll註解的方法後,我們在磁碟上獲得了包含 HNSW 結構的索引。
最後,我們開啟一個ReaderSupplier來讀取磁碟上的索引,然後使用load()將其儲存為物件。完成這些之後,我們可以驗證索引是否已持久化,並使用所需的路徑進行了適當的載入。
6. 搜尋相似向量
在本節中,我們將了解如何使用建立的磁碟索引來搜尋相似的向量。
為了說明向量搜索,讓我們在先前建立的測試類別中新增一個新的測試方法,並將索引載入到磁碟中:
@Test
void givenLoadedDataset_whenSearchingSimilarVectors_thenReturnValidSearchResult() throws IOException {
VectorFloat<?> queryVector = datasetVectors.get("said");
ArrayList <VectorFloat<?> vectorsList = new ArrayList<>(datasetVectors.values());
try (ReaderSupplier readerSupplier = ReaderSupplierFactory.open(indexPath)) {
GraphIndex index = OnDiskGraphIndex.load(readerSupplier);
SearchResult result = GraphSearcher.search(queryVector, 10,
new ListRandomAccessVectorValues(vectorsList, vectorsList.get(0).length()),
VectorSimilarityFunction.EUCLIDEAN, index, Bits.ALL);
assertNotNull(result.getNodes());
assertEquals(10, result.getNodes().length);
}
}我們先定義一個queryVector來搜尋相似的單字。我們可以選擇先前在datasetMap中填入好的單字向量表示。
然後,我們打開持久化在磁碟上的索引資源並將其載入到變數index.
之後,我們使用GraphSearch中的search()方法產生相似度搜尋結果。此方法接受幾個參數,我們來分別看一下:
-
queryVector:查詢向量 -
topK:我們想要的最相似向量的數量 -
vectors:資料集中的向量,以ListRandomAccessVectorValues格式包裝 -
similarityFunction:向量距離計算器函數 -
graph:先前建立的索引 -
acceptOrds:一個變量,可以控制哪些向量是可接受的解決方案;將其設定為Bits.ALL表示圖中的任何節點都是可接受的
執行搜尋後,我們得到一個SearchResult對象,其中包含搜尋結果向量。在我們的例子中,它包含 10 個向量,因為我們傳入了 10 作為topK 。
此外, result變數還包含有關搜尋的一些元資料訊息,例如訪問了多少個節點。
7. 結論
在本文中,我們簡要介紹了 jVector 的核心功能,包括建立索引和搜尋向量。我們也了解了 jVector 中 HNSW 和 DiskANN 結構如何確保效率和正確性。
與往常一樣,原始碼可在 GitHub 上取得。